EBNF vs. CFG
Formal grammars are often presented as Context-Free Grammars. To describe the grammar of SimpleTalk we use EBNF. Here is a discussion of why this is suitable.
In Brief
The main thesis here is that
- Languages have no intrinsic associativity; CFGs have derivations which map 1:1 to parse trees, which have specific associativity.
- Left-recursive grammars lead to infinite recursion in top-down recursive-descent parsers, BUT.. have left-associativity, which we want.
- Right-recursive grammars lead to stable top-down recursive descent parsers, BUT... have right-associativity, which we (usually) do not want.
- EBNF grammars lead to iteration rather than recursion, with a natural left-associativity, and a possible (but more roundabout) right-associativity.
- Where we actually want right-associativity (e.g. production E10 in SimpleTalk) we do in fact use recursive descent.
Example
We present the conclusion first, and then develop the argument for it.
A simple example where associativity is important is subtraction. The language and grammar are:
Language
num, num − num, num − num − num,...
EBNF Grammar
Expression ➝ num { − num }
It is crucial that this grammar is not recursive — that is, the left-hand side Expression does not appear on the right. This is what makes the language conveniently parsable with iteration.
This form is easily mapped to the parser, whose structure for building an Expression node is iterative rather than recursive, viz.:
1 function buildExpression()
2 e1 ← buildNum()
3 while token = minus do
4 skipToken()
5 e2 ← buildNum()
6 e1 ← new BinaryNode(e1, e2)
7 end while
8 return e1
9 end function
Note carefully line 6: we are replacing the expression node e1 with a new value that contains its old value as the left-hand branch of a binary expression. This left-substitution leads to the desired left-associativity.
To see this, consider the sequence of values for e1 and e2 as the function parses the expression “1 − 2 − 3”, numbered by the line numbers in the above function:
2 e1 ← 1
3
5 e2 ← 2
6 e1 ← (1, 2)
3
5 e2 ← 3
6 e1 ← ((1,2), 3)
7
8 return e1
You might hope that you could reverse the associativity by reversing the arguments to the BinaryNode() function in line 6, but this would also reverse the order of the operations, yielding a tree for 3 − (2 − 1).
It is harder to get right-associativity from a left-to-right iteration, but here is one solution:
function buildExpression()
e2 ← buildNum()
s ← new Stack
s.push(e2)
while token = minus do
skipToken()
s.push(buildNum())
end while
e2 ← s.pop()
while not s.empty do
e1 ← s.pop()
e2 ← new BinaryNode(e1, e2)
end while
return e2
end function
Right-associativity considered helpful
Where we do want right-associativity for SimpleTalk, we do in fact write the grammar recursively. For example, the list item selection expression was originally in the BNF form
E10 ➝ { item Expression of } E11
In this form E10 appeared only on the left-hand side. This production was originally parsed using the above stack-style iteration. But it proved easier to write as the right-recursive CFG
E10 ➝ item Expression of E10 | E11
Note the difference: E10 appears on both sides of the rule. The SimpleTalk parser now uses this structure to parse the item construct:
function buildE10()
if token = item then
skipToken()
index ← buildExpression()
acceptToken(of)
e10 ← buildE10()
return new ItemNode(index, e10)
else
return buildE11()
end if
end function
Remarks
CFGs are commonly used to describe formal languages, particularly when the generation of parsing is to be automated. This helps ensure that the language recognized by the parser is the one intended by the designer. The SimpleTalk compiler is (currently) written from scratch, and comprises about 2000 lines of JavaScript. (And about 1200 lines of Objective-C in the OSX/iOS version.) We have used EBNF, which can map directly to a less-recursive parser and provides left-associativity in the bargain.
To explore this, we start from the most basic example and work forward. Here are the languages, and their grammars that we will discuss. They are presented up-front, and in parallel for easier direct comparison. Following each grammar is a discussion.
Zero-or-more repetition
Language: ε, a, aa, aaa...
EBNF: A ➝ { a }
Left-recursive CFG
A ➝ ε | Aa
Right-recursive CFG
A ➝ ε | aA
The direct application of top-down, recursive descent to parsing the left-recursive production would be:
function parseA()
if token ≠ a then
return
else
parseA()
acceptToken(a)
end if
end function
which is head-recursive and will never finish for any non-empty string of as. In other words, left-recursive grammars are better suited to bottom-up parsing.
Transforming this grammar into right-recursion is simply a matter of reversing the first production, as shown above. That results in a grammar that translates into this parser:
function parseA()
if token ≠ a then
return
else
acceptToken(a)
parseA()
end if
end function
Conclusion: right-recursive grammars are better suited for top-down parsing. (If a grammar has no recursion, its productions are too limited for a general programming language.) However, the right-recursive grammar leads to right-associativity, as the next example will show.
One-or-more repetition
Language: a, aa, aaa...
EBNF: A ➝ a { a }
Left-recursive CFG
A ➝
a |
Aa
Derivation of aaa
A ➝
Aa ➝
Aaa ➝
aaa
Parse tree of aaa
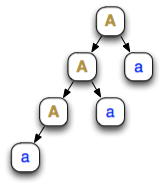
Right-recursive CFG
A ➝
a |
aA
Derivation of aaa
A ➝
aA ➝
aaA ➝
aaa
Parse tree of aaa

Now consider the expression aaa. Its left-recursive derivation and parse tree are shown above: the tree implements left-associativity.
By contrast, using the right-recursive grammar for the same production yields right-associative tree. This grammar leads directly to a recursive top-down parse algorithm:
function parseA()
if token = a then
skipToken()
parseA()
else
return
end if
end function
More to the point, we would construct a parse tree like so:
function buildA()
if token = a then
skipToken()
return new BinaryNode(a, buildA())
else
return new EmptyNode
end if
end function
As the tree shows, right-recursion leads to right-associativity. You might think that you could reverse the associativity by reversing the arguments to the BinaryNode() function, but this would in fact reverse the order of the operations.
To sum up: a CFG comes not only with a language it generates, but a derivation for each production that is unique (for unambiguous languages) and is isomorphic to a parse tree that is biased to the left or right side. And although we may be indifferent to what the derivation is, we care about the shape of the parse tree, because it determines associativity.
Subtraction Expressions
Language: num, num − num, num − num − num......
EBNF: E ➝ num { − num }
Left-recursive CFG
E ➝
E −
num |
num
Derivation of 1 − 2 − 3
E ➝
E −
3 ➝
E −
2 −
3
➝
1 −
2 −
3
Parse tree of 1 − 2 − 3
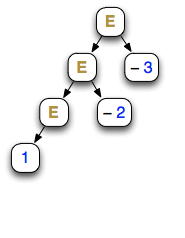
Left-associative: (
1 -
2) -
3
Right-recursive CFG
E ➝
num moreNums
moreNums ➝ −
num moreNums | ε
Derivation of 1 − 2 − 3
E ➝
1 moreN ➝
1 −
2 moreN ➝
1 -
2 −
3 moreN ➝
1 −
2 −
3
Parse tree of 1 − 2 − 3
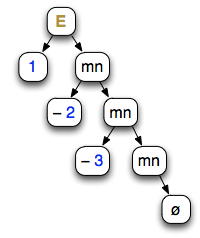
Right-associative:
1 − (
2 −
3)
Here we see the advantages and shortcomings of each approach. The left-recursive grammar leads to a left-associative tree. But it cannot be implemented directly with top-down recursion. Moreover, examine its derivation: it proceeds backwards from the last number to the first. This is one reason that LR grammars and LR parsers can be hard to understand. (See shift-reduce conflicts.)
By contrast, the right-recursive grammar leads directly to a top-down recursive implementation...that has the wrong associativity for subtraction.
In view of the foregoing, using EBNF grammar and its corresponding iterative parsing implementation provide the best of both worlds.